
GPT 5.4, Ranked
OpenAI released GPT 5.4 yesterday, so we took the opportunity to evaluate not only 5.4 but also catch up with 5.3 Codex, which was not yet available in the API when we were running the tests for the February Power Ranking.
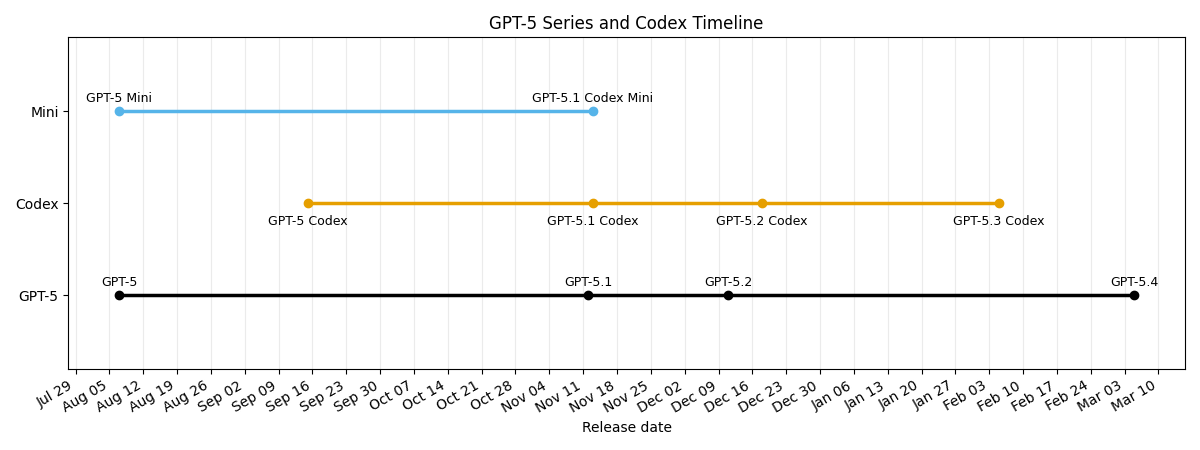
If you're thinking "but didn't they just release 5.3 a month ago?" you're not alone, OpenAI has been releasing models at a breakneck pace since 5.1 in November:
We're here now to answer two questions:
- Is the slowly-increasing price of the 5.x series justified?
- Which is the best OpenAI coding model today?
Putting the Power in Power Ranking
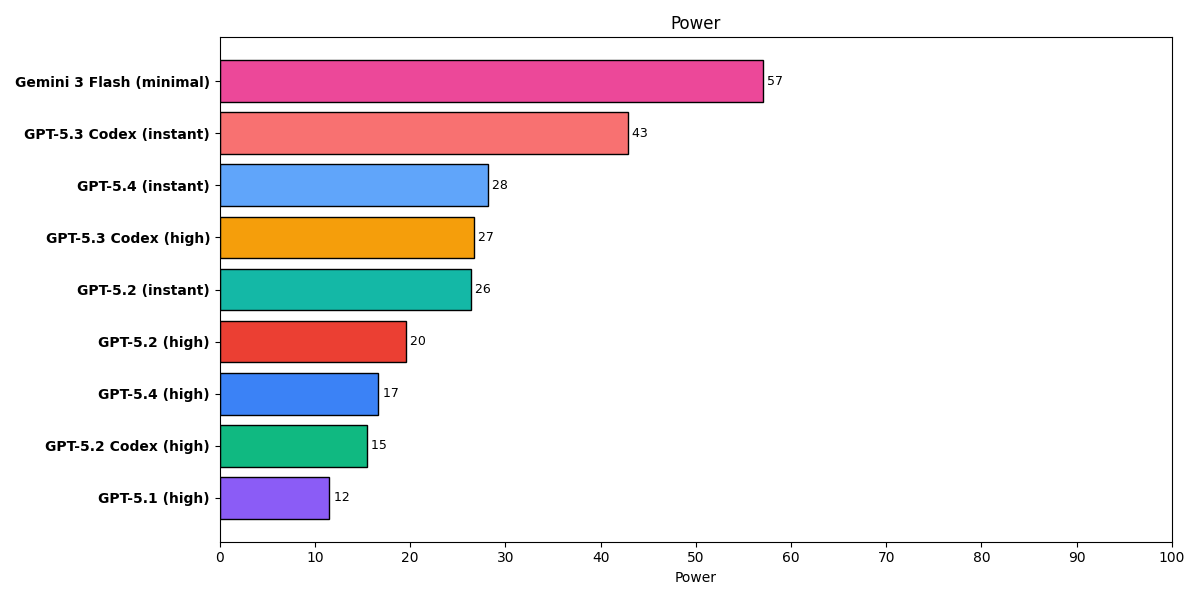
Unlike most benchmarks, which only report pass/fail rates (or sometimes ELO, which is a measure of success relative to peers), our Power Ranking reports pass rate, cost, and latency. It can be hard to compare three independent variables in your head, and we've received some criticism for not strictly following the pass count in our tier lists. The chart at the top introduces the synthetic power metric, where power = score * speed * value, with speed the square root of inverse latency and value the square root of inverse cost. (This means that score, as the only linear-weighted term, is the most important.) Here's how these combine for the GPT family, again including our S-tier champ Flash for comparison:
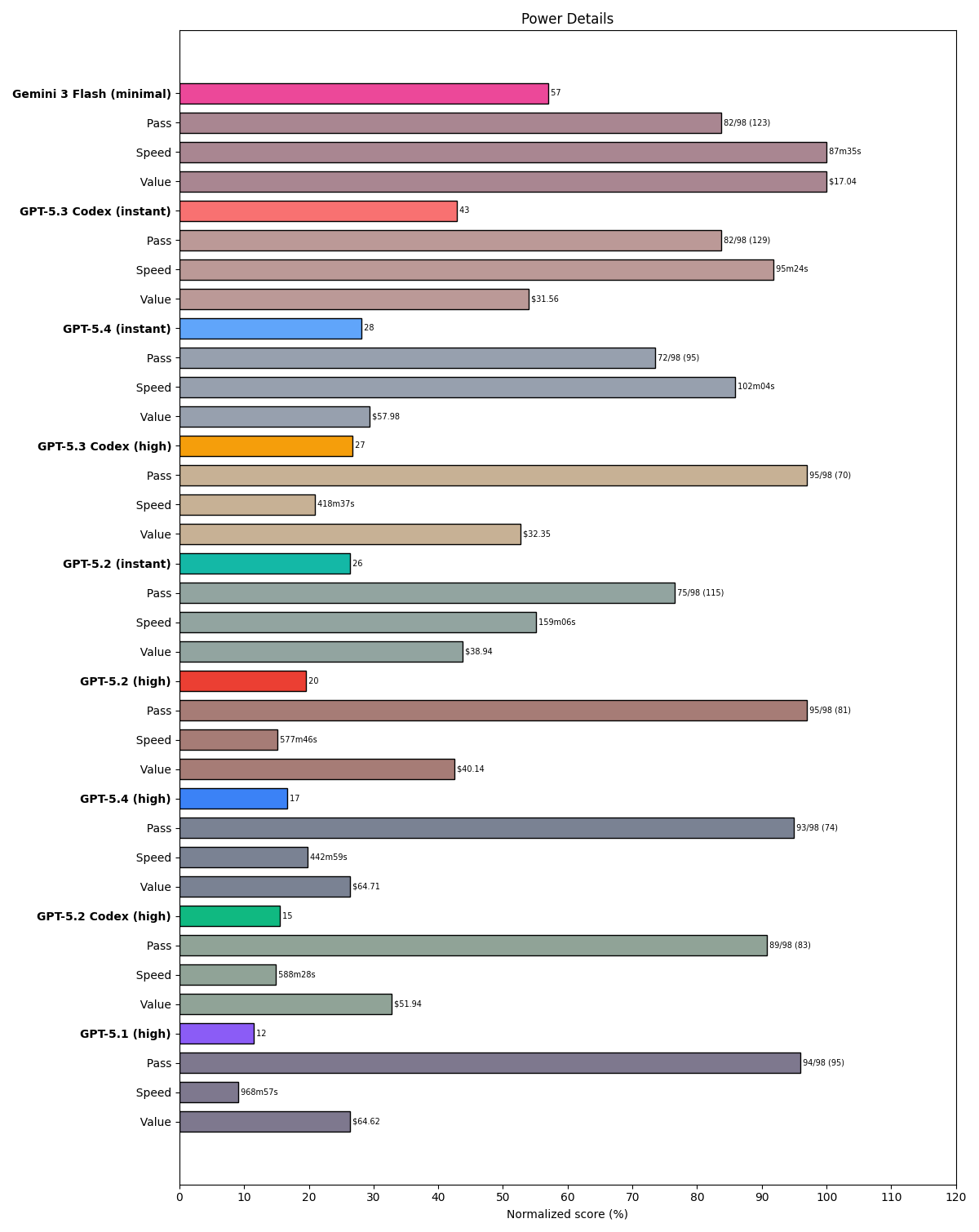
Are the price increases justified?
This is a mixed bag, because there are 3 different price points across 5 different models:
- GPT-5.1: $1.25 / $10
- GPT-5.2, GPT-5.2 Codex, GPT-5.3 Codex (and the barely-released, instant-only GPT-5.3): $1.75 /$14
- GPT-5.4 (and presumably 5.4 Codex coming soon): $2.50 / $15
What we're seeing in our tests is:
- GPT-5.2 and 5.2 Codex are modestly better than GPT-5.1 and worth the price increase
- GPT-5.3 Codex is faster and smarter than 5.2 and the same price per token
- GPT-5.4 falls off vs 5.3 Codex in both instant and high reasoning modes. Not worth it!
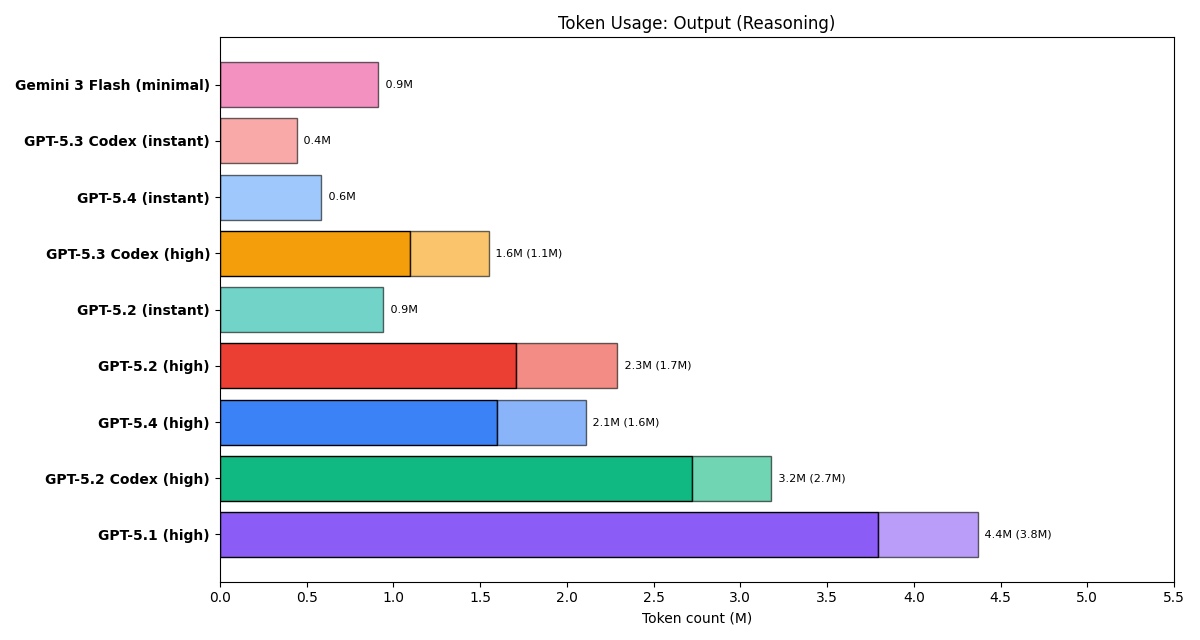
Fewer Tokens, Better Results
OpenAI has claimed that one of the justifications for its price increases is that the newer models use fewer tokens. We find that this is true for 5.1 to 5.2, and 5.2 Codex to 5.3 Codex. We do not see this happening for vanilla 5.2 to 5.4:
The Best Coding Model in OpenAI's stable
After 5.1 Codex Mini underperformed 5 Mini by a solid margin and the full sized 5.2 Codex posted worse results than vanilla 5.2, we concluded that the Codex model family was overtuned for the codex harness to the point of harming its performance elsewhere. So we're pleased to see that 5.3 Codex does not follow this trend and is in fact unambiguously OpenAI's best coding model to date. We've updated Brokk to make this the default coding model when you enable OpenAI oauth.