
GPT-OSS Underperforms in Independent Testing
We put OpenAI's newly released GPT-OSS model through our own independent benchmark, the Brokk Power Ranking, to see how it really performs on coding tasks.
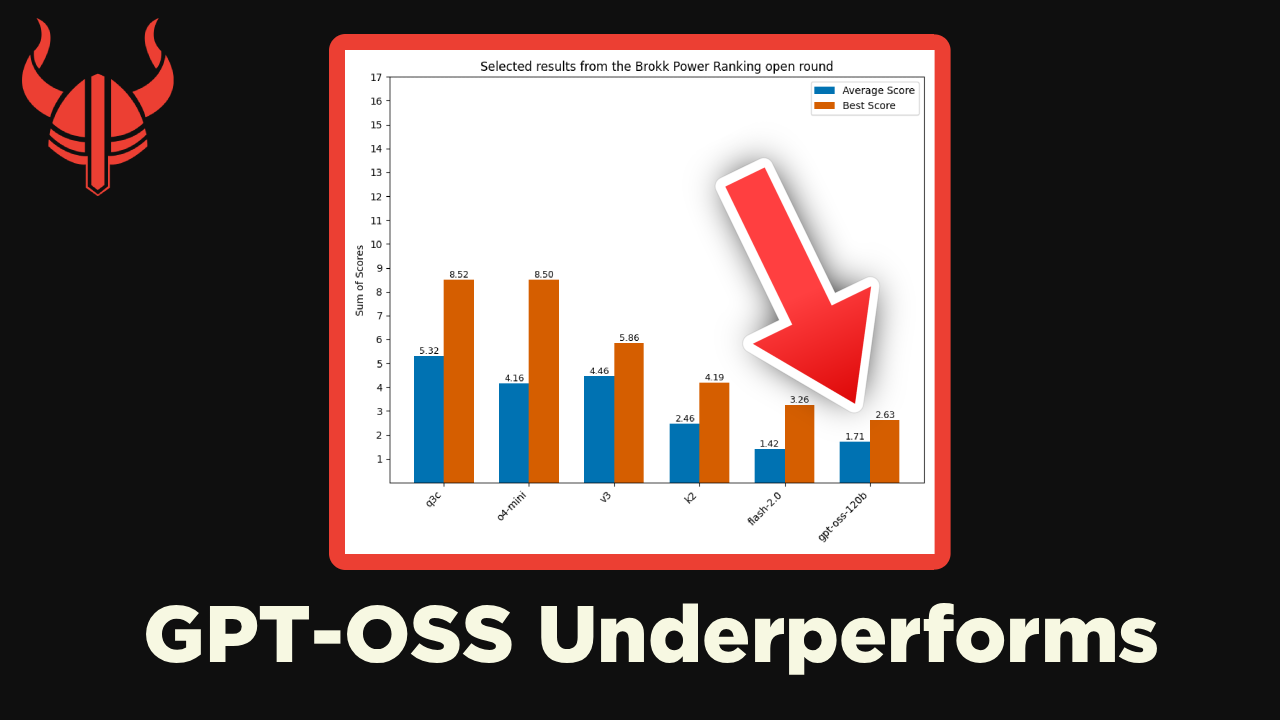
We put OpenAI's newly released GPT-OSS model through our own independent benchmark, the Brokk Power Ranking, to see how it really performs on coding tasks.
While OpenAI highlighted strong performance in their launch blog, especially on a single coding benchmark, our results tell a different story. In this video, Jonathan from Brokk walks through how GPT-OSS stacks up against other popular open-weight and proprietary models, including GPT-4 Mini, Flash 2.0, and several others.
Highlights:
- A look at the benchmarks OpenAI showcased (and what they didn’t)
- How GPT-OSS performed in real-world coding scenarios
- Comparisons with leading open models
- Why these results matter for developers and researchers
Spoiler: GPT-OSS landed near the bottom of the pack in our tests, despite its impressive accessibility and hardware efficiency.



