
The 26.02 Coding Power Ranking
For 2026, we’ve split the Power Ranking up into Planning and Coding tasks. This ranking reports only coding performance; you can be among the first to see our planning results by subscribing to our newsletter.
We did this because using a single model for both planning and coding is more expensive and slower than letting your planning model carve the problem up into coding-model-sized-tasks. Midsized models like Gemini 3 Flash are already more than good enough to offload coding from your flagship-sized planner, and this class of models is only going to continue getting better.
Coding is solved
Even with the hardest problems in our dataset, covering tasks requiring edits of over 20 files, the top models are passing well over 90%.
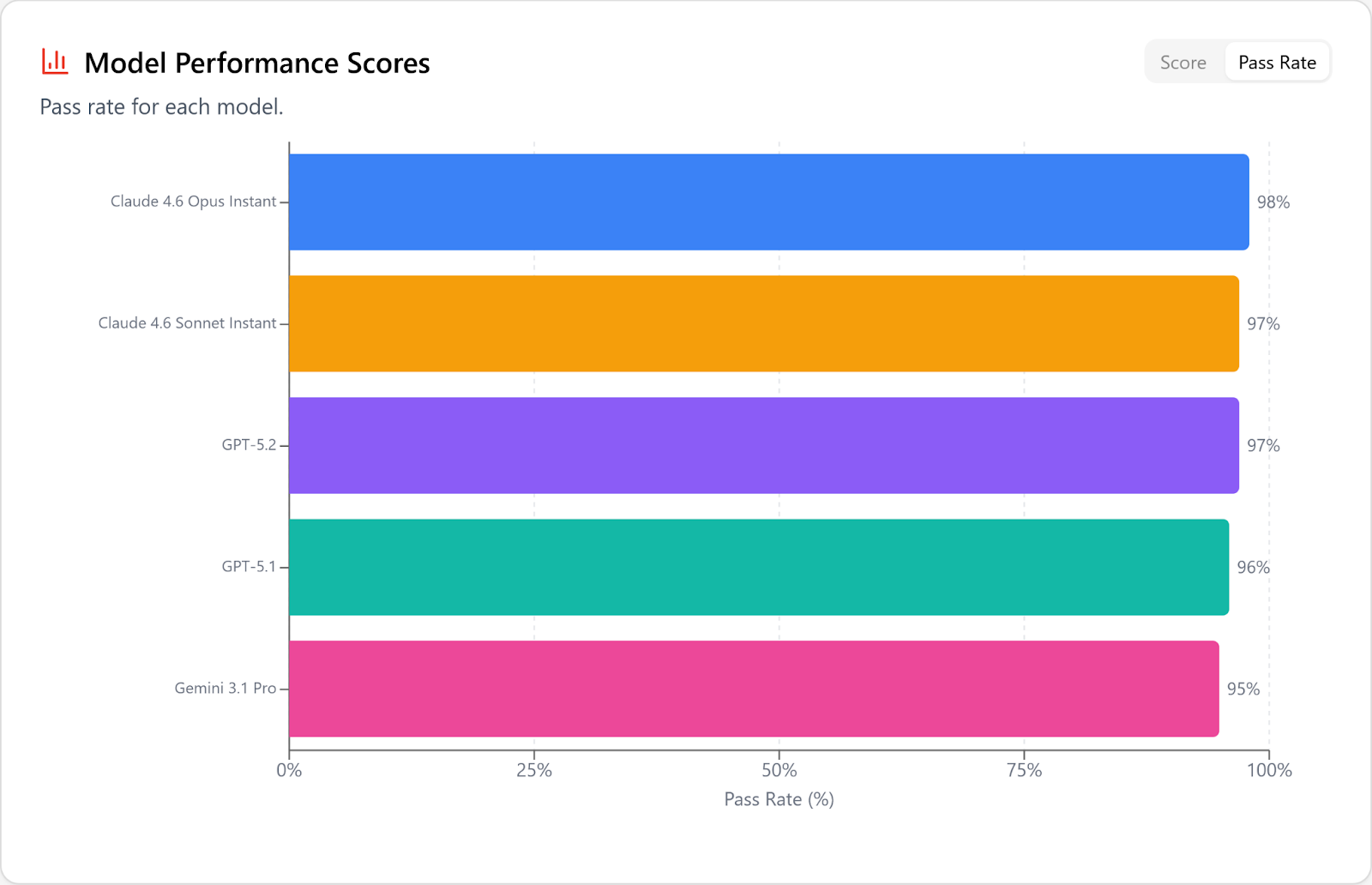
From here on out (for coding! not for planning!) the entire game is speed and price, and the 26.02 tier list reflects this.
Flash 3 is (still) the best coding model and nobody is close
We called this out when we first tested Gemini 3 Flash in December, and it repeated its dominating performance this time around against a completely different set of coding tasks.
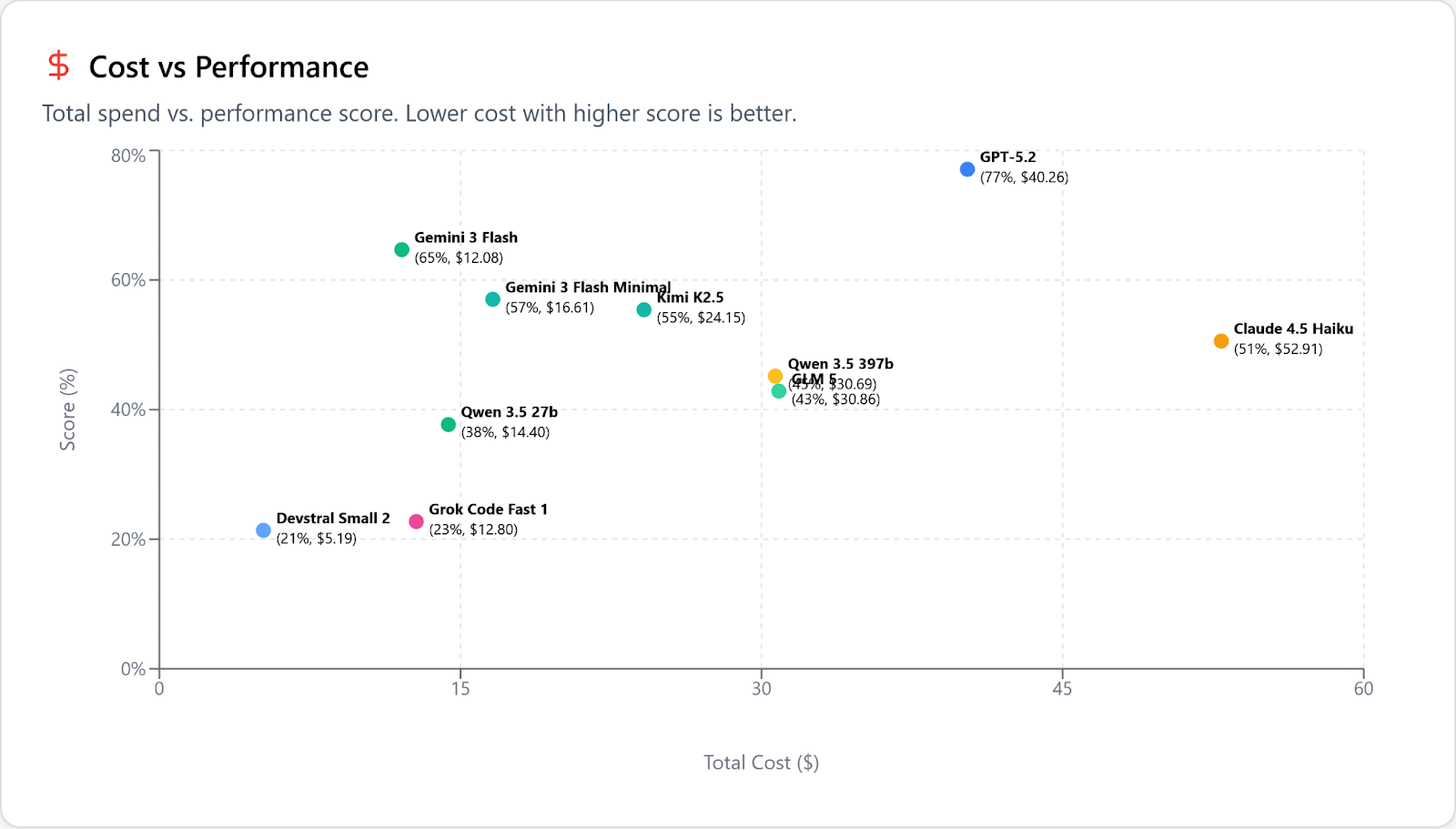
“The best” is a strong statement, and you’d expect us to need to qualify it, to carve out exceptions. And fine, you’re right, if you look at cost vs performance it’s true that GPT-5.2 (and Gemini 3.1 Pro) can make sense if you are working on the very hardest problems that Flash struggles with. In this graph we’ve removed models that are more expensive (but not smarter) than GPT 5.2 to declutter the results:
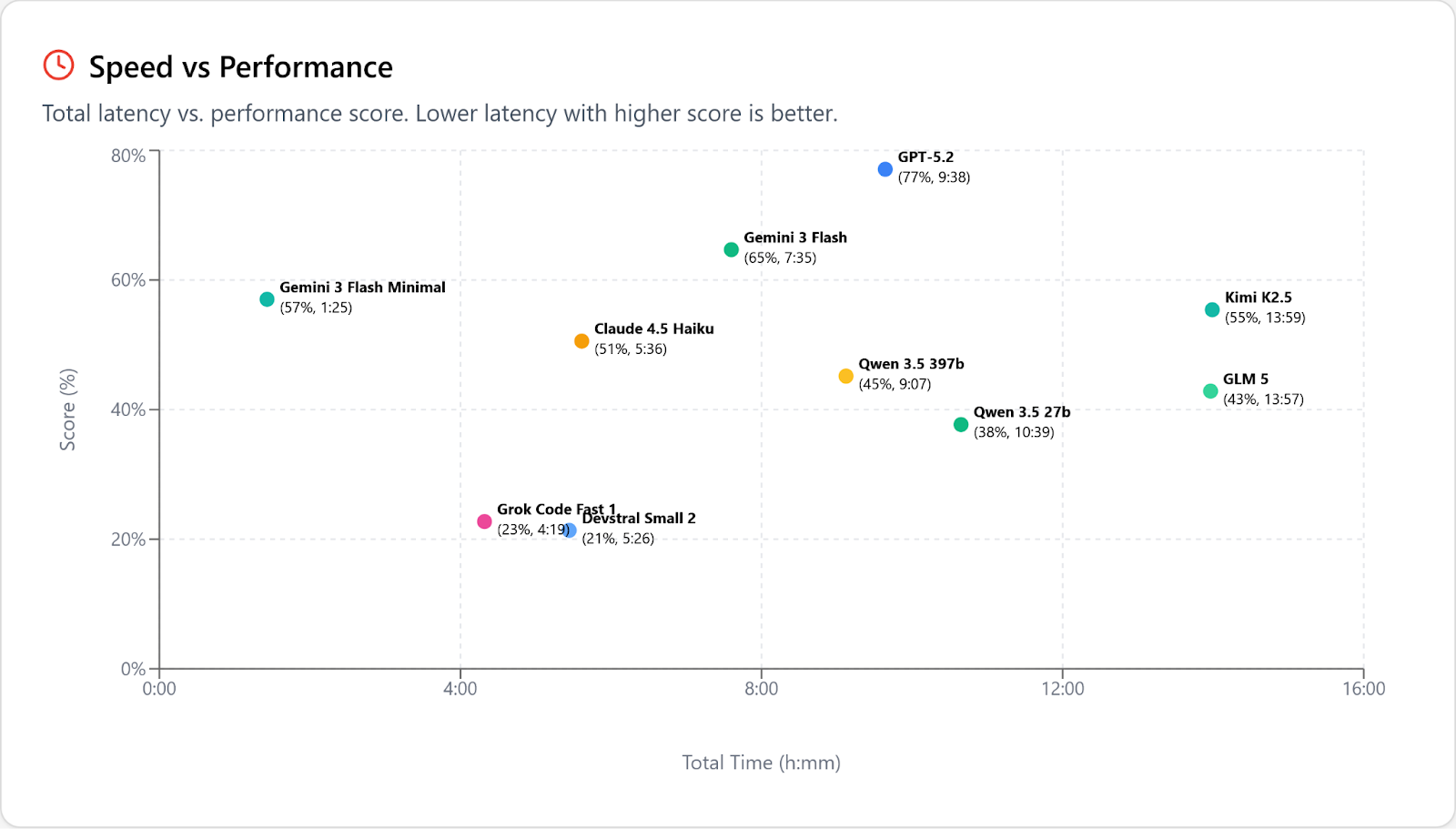
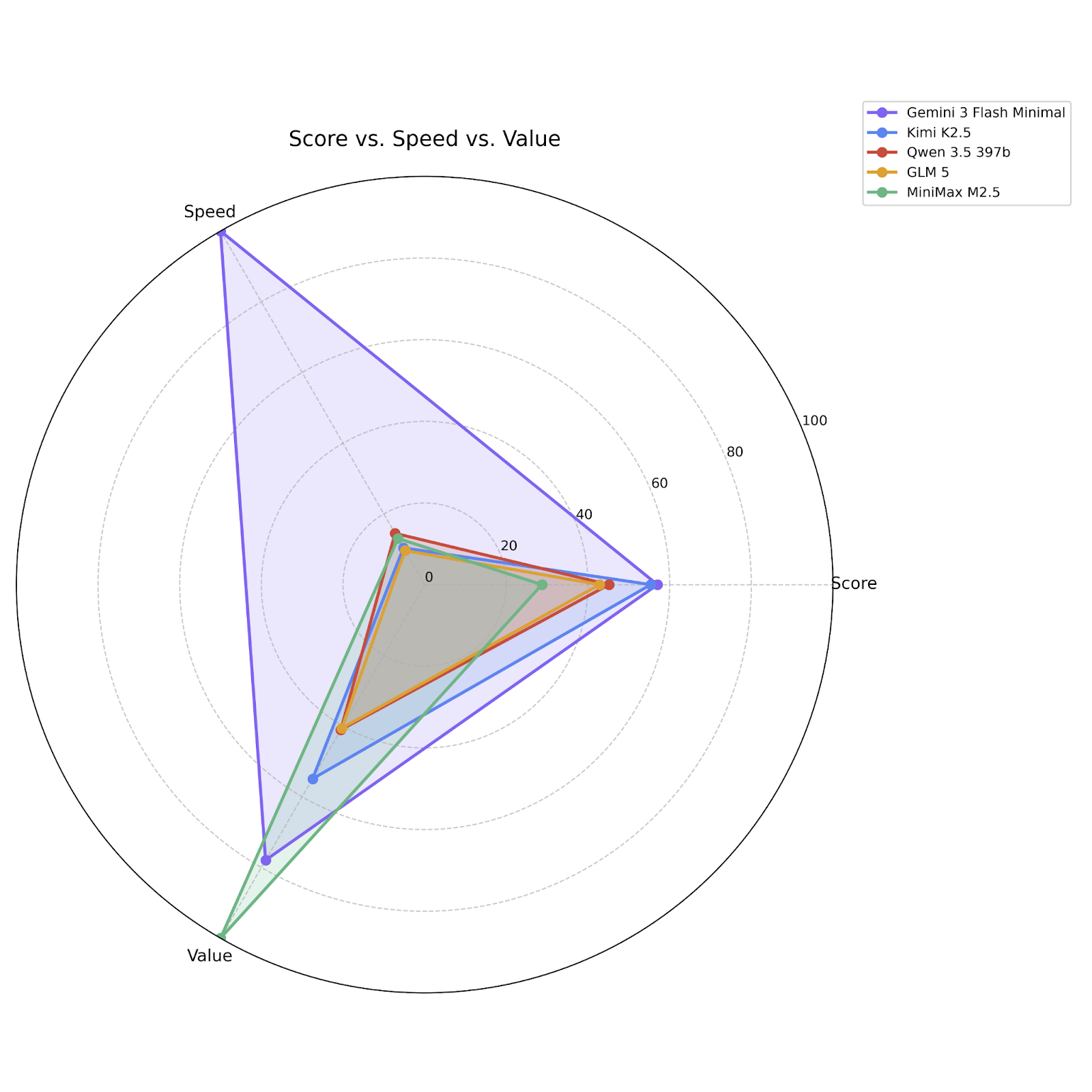
But look at performance vs speed. This is just a bloodbath; Flash/Minimal is twice as fast as the much dumber Grok Code Fast 1 and over 3 times faster than the next-fastest actually-smart model, Haiku. The next fastest after THAT is … Flash 3/High:
If you’re still not convinced, here’s a visualization of Flash 3 and its closest competitors across all three metrics:
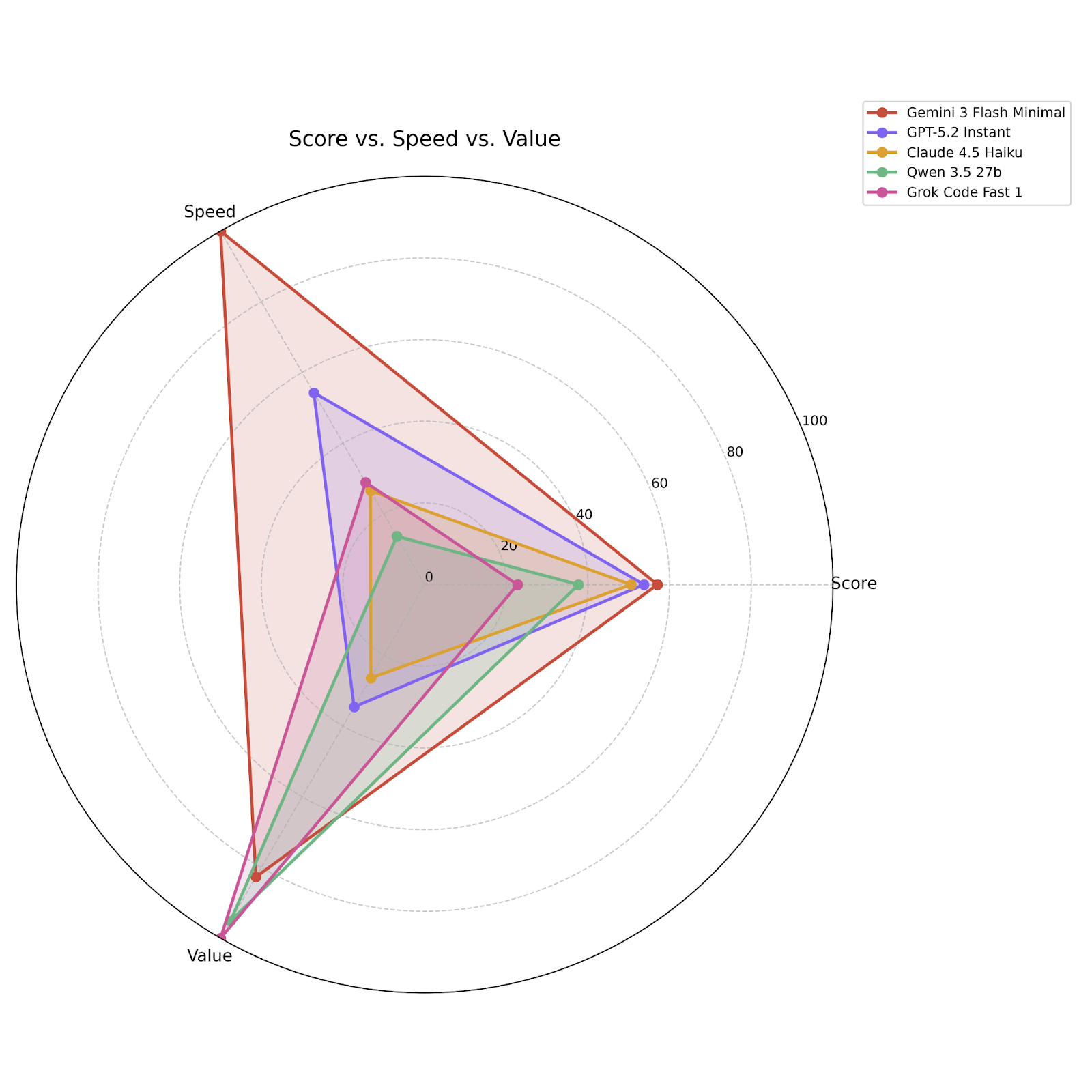
Friends don’t let friends code with Anthropic models
Look, Anthropic models are plenty smart. They’re also reasonably fast, if you disable thinking. But good god they are so so so expensive and not in a “yeah all the flagships are expensive” kind of way:
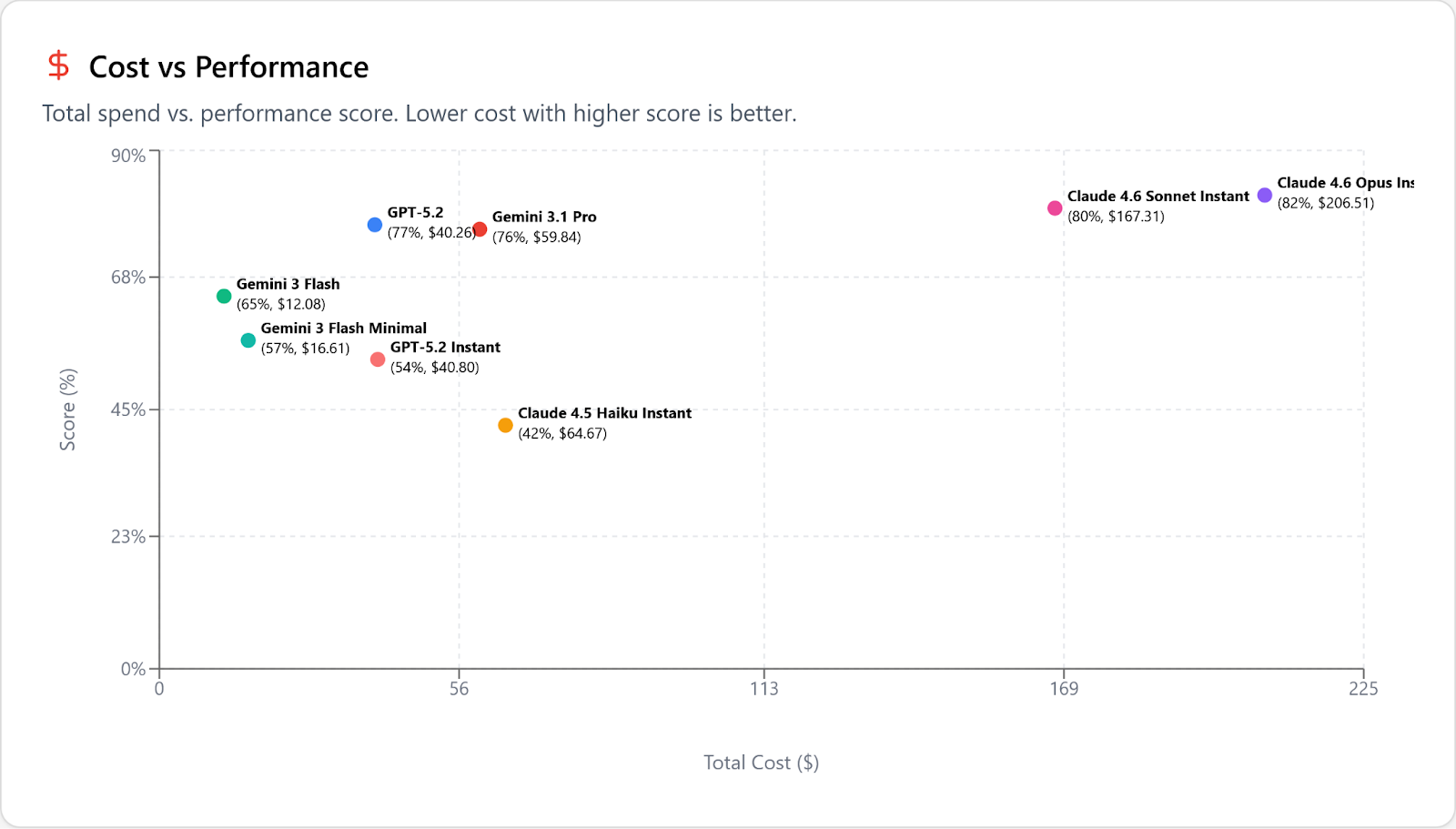
Remember: coding is solved! which is a short way of saying, there’s a ceiling here and everyone is starting to hit it, so it’s foolish to pay literally 10x more than necessary. (This gets even worse if you are using the new large context beta feature; Anthropic is following Gemini’s lead in charging 3x for requests whose input token counts are over 200k.) Again: we’re talking only about code-authoring here, not making claims about researching or planning.
Local models are finally usable, if you’re patient
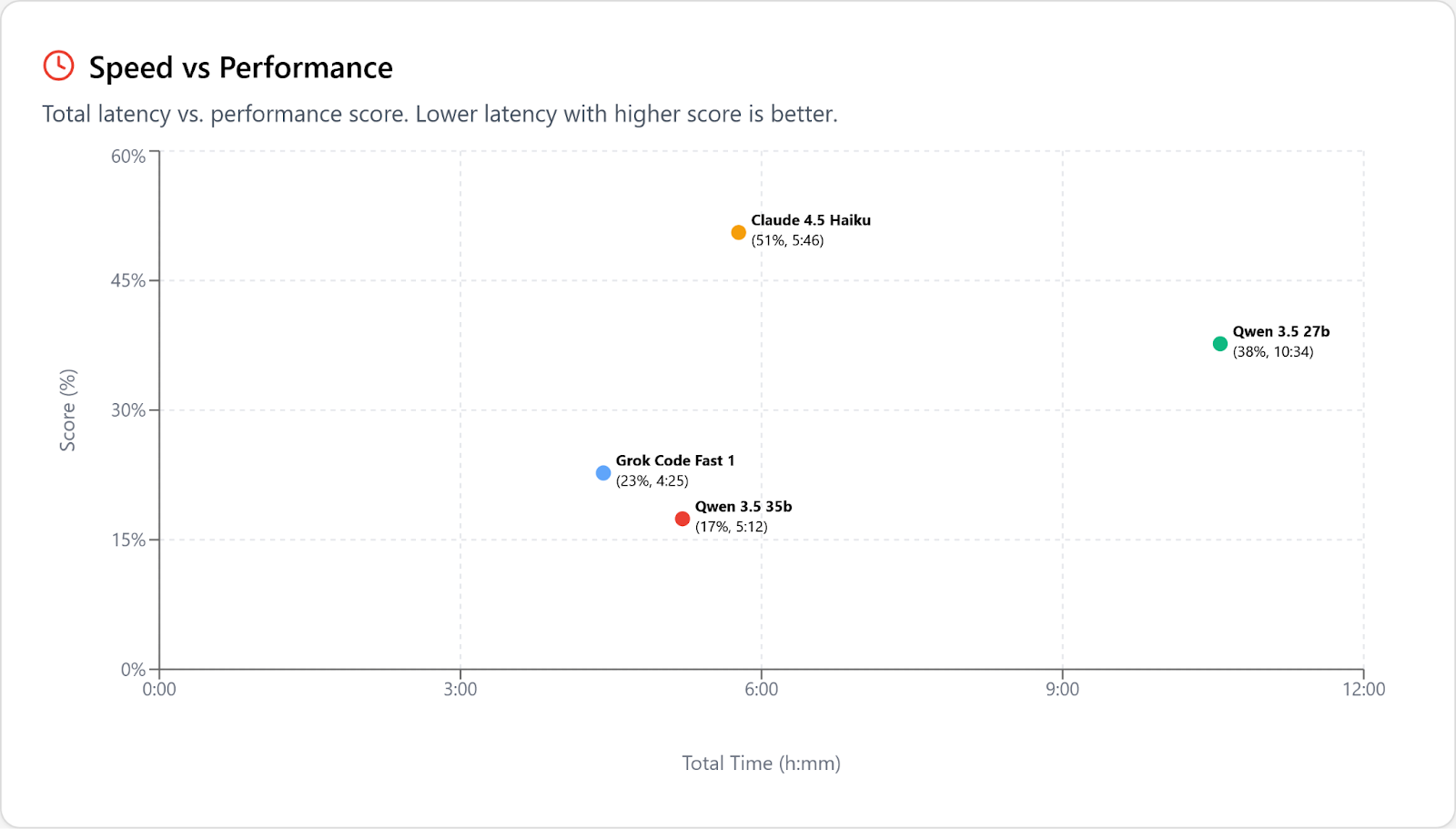
In December, Devstral Small 2 was the first open-weights, local-sized model that passed our tests at a level of smarter-than-GPT-5-nano, and last week Qwen 3.5 27b blew past that bar decisively, passing the (significantly larger) GPT-OSS-120b and nearly catching up to Haiku 4.5, which as recently as November was arguably the best coding model available. Alibaba says that the dense 27b model performs at the level of their 122b MoE; if anything that is understated: 27b very nearly matches the flagship 397b (also MoE).
The other local-sized Qwen 3.5 is a 35b MoE, which is about twice as fast and half as smart as 27b. This drops it under the level of intelligence where it's possible to get work done without a ton of frustration, so it's a bad trade. Here’s both of them, bracketed by GCF1 and Haiku:
As I wrote in December, speed is the final boss for open weights models. Qwen 3.5 27b is roughly 10x slower than Flash 3 at solving our tasks, and that’s against Alibaba’s API, served 3x faster than you’ll see locally on a better GPU than most people have. So if you’re looking to get work done, it’s more of a novelty than a practical solution. Adding Flash 3 to the chart:
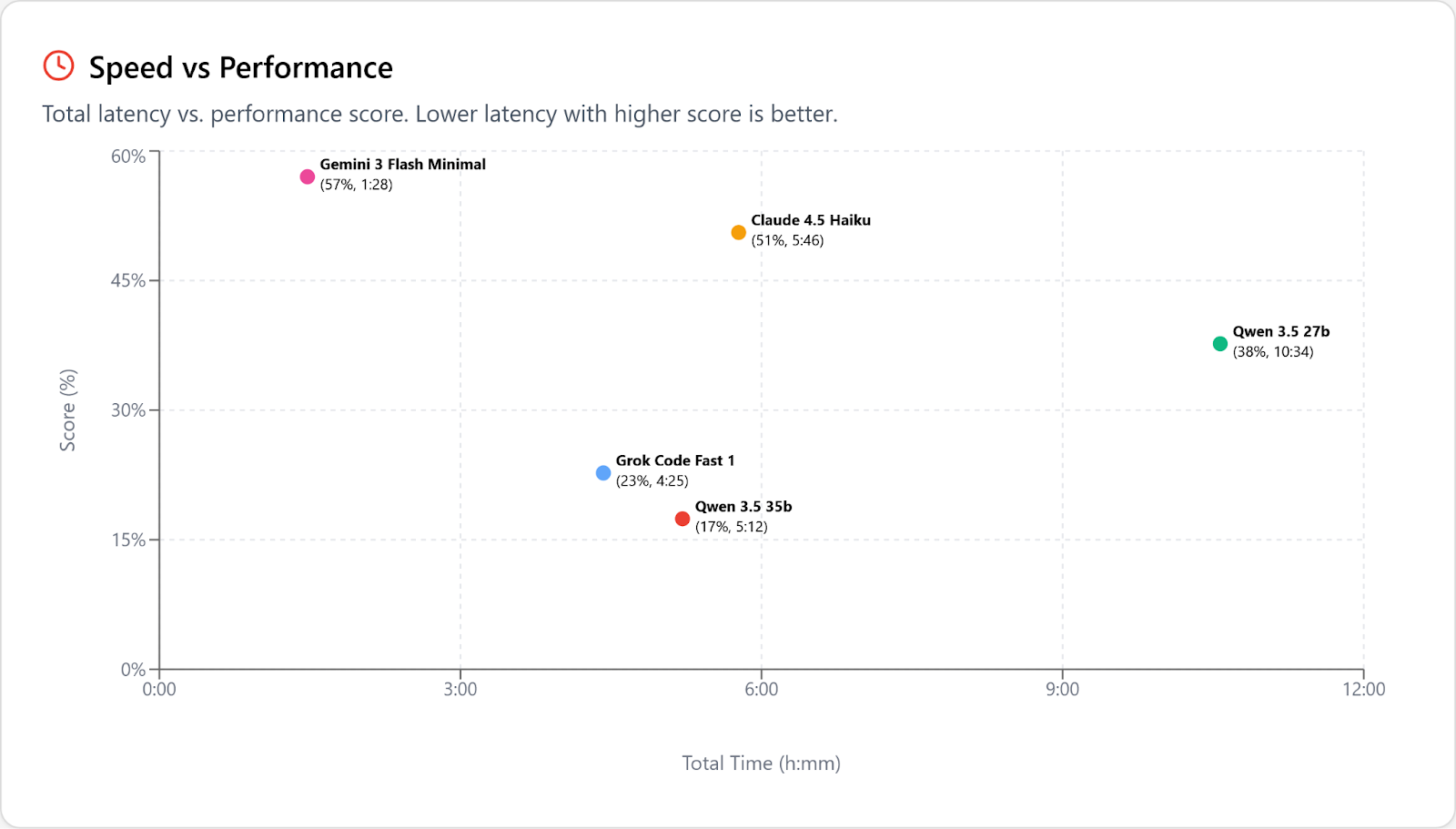
But it almost seems rude to mention practicality here. Qwen 3.5 27b is an amazing achievement!
The other open models
Moonshot AI’s strategy of going as big as possible (and distilling Anthropic’s work) is paying off. After K2 and K2 thinking being D-tier also-rans last year, K2.5 has taken the crown of smartest open-weights coding model. (This cost our founder $20 in a lost bet with our director of marketing.) You can also check out the Open Round to see the models that didn’t make the cut as finalists.
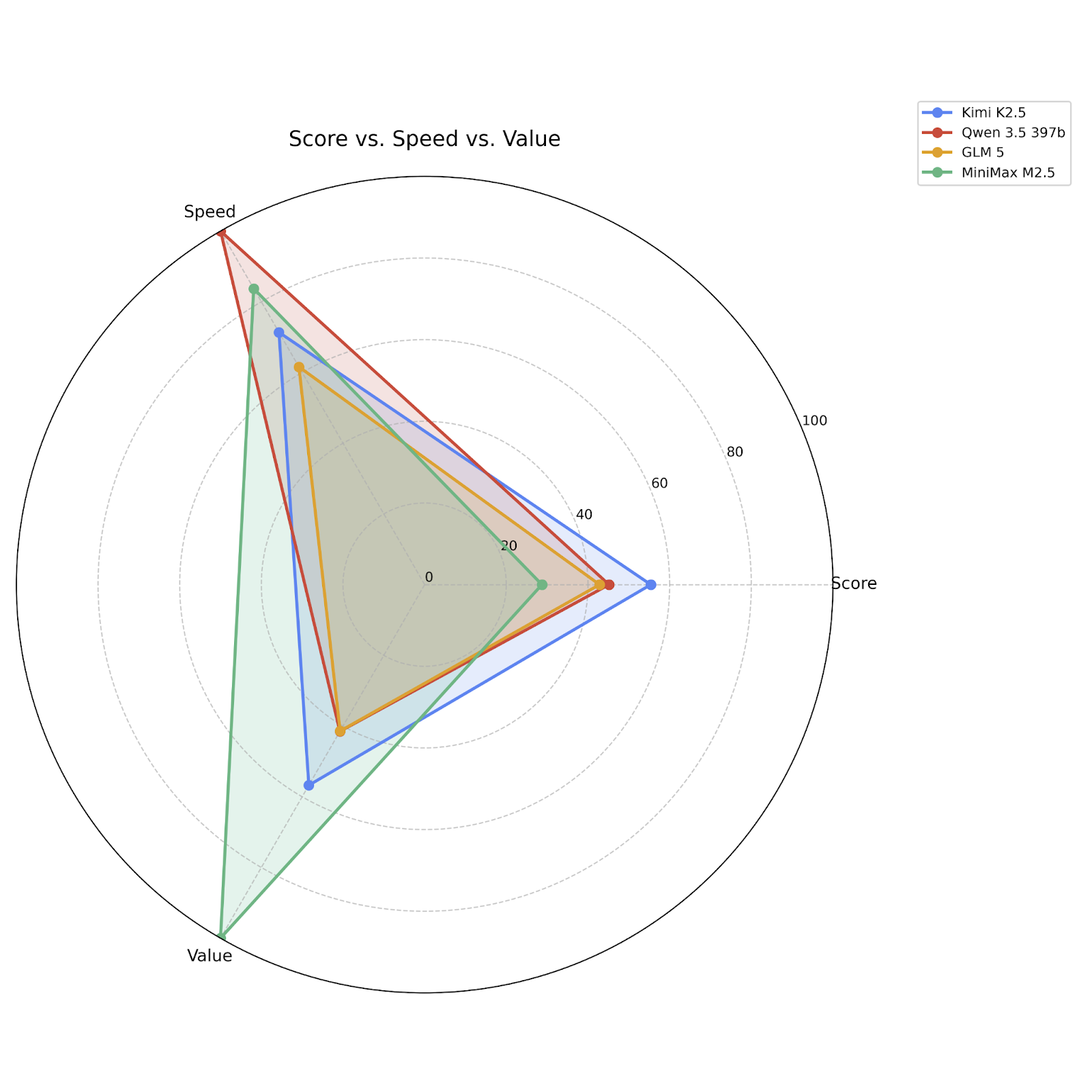
But if your question is “which one of these should I write code with”, the answer is “none of them,” because in case you weren’t paying attention, the answer is … Flash 3.
Miscellaneous findings
- Gemini 3.1 Pro seems to have solved the thinking-loop problems that we saw with Gemini 3 Pro; we didn’t hit this a single time in our testing. This leaves 3.1 Pro, like the other flagship models, a good model that is too slow and expensive to be your coding daily driver.
- Sonnet 4.6/High failed several tasks that Instant succeeded at. This turns out to be caused by overthinking: Sonnet 4.6 would literally max out its 64k output tokens budget on reasoning, and hit the wall before it actually wrote any patches. Opus 4.6 also thought a lot, but its max output tokens is 2x larger, and that was enough to not stall out like this.
- GPT-5.2 Codex is a bit worse than vanilla GPT-5.2; GPT-5.1 Codex Mini is a lot worse than vanilla GPT-5 Mini. OpenAI isn’t kidding when they say that these models are specifically trained to work with their
codexcoding harness and work poorly outside of it. (GPT-5.3 Codex is untested because it is not yet available in the API.) - Cheaper isn't always cheaper. Both GPT-5.2 and Flash 3 were less expensive with thinking enabled, even though it uses more reasoning tokens, because it took fewer tries to solve the tasks.
Model Settings
- We’ve used Anthropic’s “Instant” term for “thinking disabled” in both Anthropic and OpenAI models. For Gemini models we use Minimal, which is for now only supported by Flash. If reasoning is not specified in a model label in the results, then it’s set to High where reasoning effort is supported. (Most open weights models do not support configuring reasoning effort.)
- Anthropic models were tested with adaptive thinking and 1M context enabled.
- Open weights models were tested against first party providers on Openrouter where that was an option; otherwise, against high quality third parties like Parasail and Together. Anthropic, Gemini, Mistral, OpenAI, and xAI were tested directly against their creators’ endpoints.
About the benchmark
Some things haven’t changed since 2025; SWE-bench still sucks, and MiniMax is still benchmaxxing their hearts out. We still need uncontaminated benchmarks that nobody has had the chance to train on yet.
For 26.02, we took the lessons from our first run and made a few deliberate changes. Most notably, we pulled planning out of the coding ranking entirely, and when we rebuilt our task set we included C# and Go projects for the first time. But we’ve also tweaked our testing and reporting setup. Specifically:
- Instead of running all tasks 3x and reporting both average and best, we’re running failed tasks a second time and rolling those numbers in as success-with-turn-penalty. So if a task fails after 5 build attempts in run 1, and succeeds after 2 builds in run 2, it will be scored as success-after-7-builds.
- We’re reporting an estimated cost-to-solve and time-to-solve that takes into account performance on successful tasks and task difficulty as observed across all models. This gives us a more accurate picture of “How cost effective or how fast is this model, given a task that is simple enough for it to solve?” which is what most people expect intuitively.
However, for the Open Round, many of the models do not solve enough tasks to calculate this accurately, so we are falling back to reporting total cost and total latency instead. This tends to overpenalize weaker models, since they max out their retry count with nothing to show for it on many tasks, but only counting successful tasks penalizes the smarter models that solve more, so reporting the total numbers seems like the lesser evil.
We’re still calculating “Score” as 1 / log2(b + 2), where b is the number of failed builds; this gives a partial credit for success that decays more as you take more attempts, but we’re also reporting raw pass rate now as well.