
The Best LLM for Code
I’ve been using Brokk to build Brokk for several months, so I have strong opinions about the best models to use for code.

I’ve been using Brokk to build Brokk for several months, so I have strong opinions about the best models to use for code.
(Brokk is an open source IDE (github here) focused on empowering humans to supervise AI coders rather than writing code the slow way, by hand. So Brokk focuses not on tab-completion but on context management to enable long-form coding in English.)
The bad news is that there’s no single answer that’s best for everything, although Gemini Pro 2.5 currently comes very close. The good news is that different models are good at different things, so you can improve your outcomes if you play to their strengths.
A note on terminology
Architect, Code, Ask, Edit, and Search are all Brokk agents that you can invoke:
Brokk allows configuring models for each agent separately.
Brokk additionally gives you fine-grained control over model reasoning. Essentially, model vendors figured out that allowing the model to “think” (essentially: to talk to itself) before answering improves its effectiveness; the Reasoning setting allows configuring that as low, medium, or high; the tradeoff is that higher levels of reasoning are slower and more expensive, since reasoning is billed at the more expensive output token rate.
Usually, but not always, the default reasoning is medium; for Sonnet 3.7, the default is to leave it off.
With that in mind, here are three different sets of models that all make sense for different use cases.
The Vibe Coder
Here’s how I configure Brokk 90% of the time:
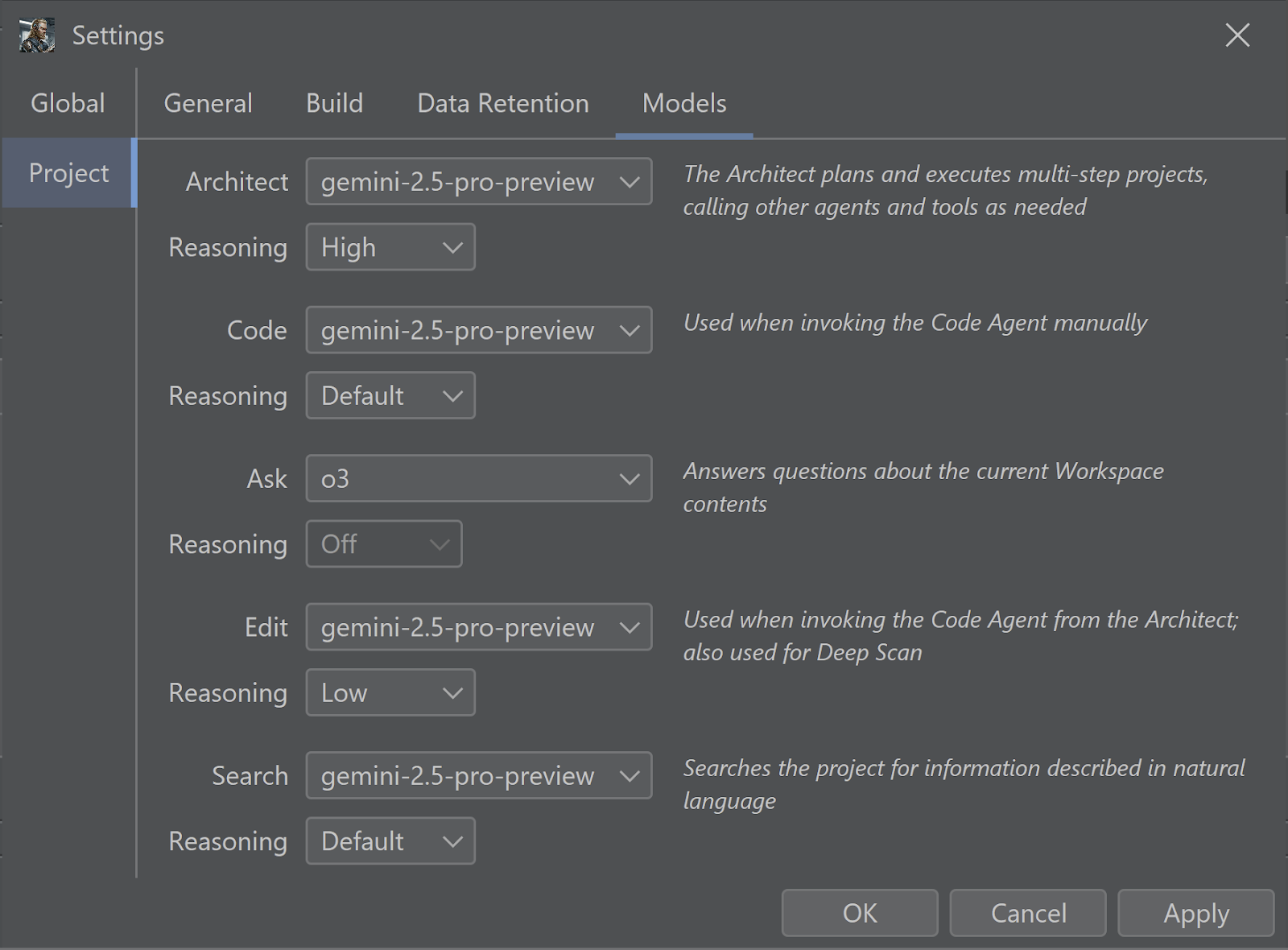
I’m relatively cost-insensitive and I’m willing to pay more for better results. So I configure Ask to use o3, the smartest model available. (Ask + o3 is particularly good at root-causing bugs.)
But I don’t use o3 to write code, because o3’s attention to detail is not great. So Gemini 2.5 Pro takes that role for me. I dial the Reasoning setting down to Low in the Edit role, since the Architect model is providing detailed instructions.

Possibly because of that attention-to-detail problem, o3 is also terrible at both tool calling and structured outputs, so I use Gemini 2.5 Pro with reasoning dialed up to High to power the Architect.
Search also relies on tool calling, so Gemini 2.5 Pro gets the nod from me there as well.
NB: As of this writing, there is a glitch in the litellm metadata for o3 that causes the Reasoning dropdown to be disabled. This results in it running with default (medium) reasoning, not with no reasoning at all.
The Careful Professional
My colleague Lutz Leonhardt prefers this:

When editing manually (that is, prompting Brokk directly instead of going through the Architect), Lutz prefers to Ask first to generate a plan, iterate if necessary, and then Code to that plan, while I prefer to go directly to Code.
So for me it’s more important to have Gemini’s intelligence advantage in the Code process, but Lutz values Sonnet’s better instruction-following more highly. Meanwhile, since he is an active participant in the design process, it’s more important to have Gemini 2.5 Pro’s speed for Ask, than o3’s raw intelligence. (But he does bump Gemini 2.5 Pro’s reasoning to High in an attempt to get the best of both worlds.)
Lutz puts Search on Sonnet 3.7 because, well, mostly because he likes Sonnet. Lots of models work fine for Search, and Sonnet’s advantage in tool calling is enough to make up for any deficit in raw intelligence compared to Gemini Pro.
Lutz keeps Edit on Gemini Pro because of its secondary function: the Edit model is also used for Deep Scan to find code related to your current instructions, and Deep Scan benefits from Gemini’s much larger context window compared to o3 or Sonnet 3.7.
The Value King
If you want to keep your costs absolutely as low as possible while delivering a strong coding performance then the main game in town is DeepSeek:
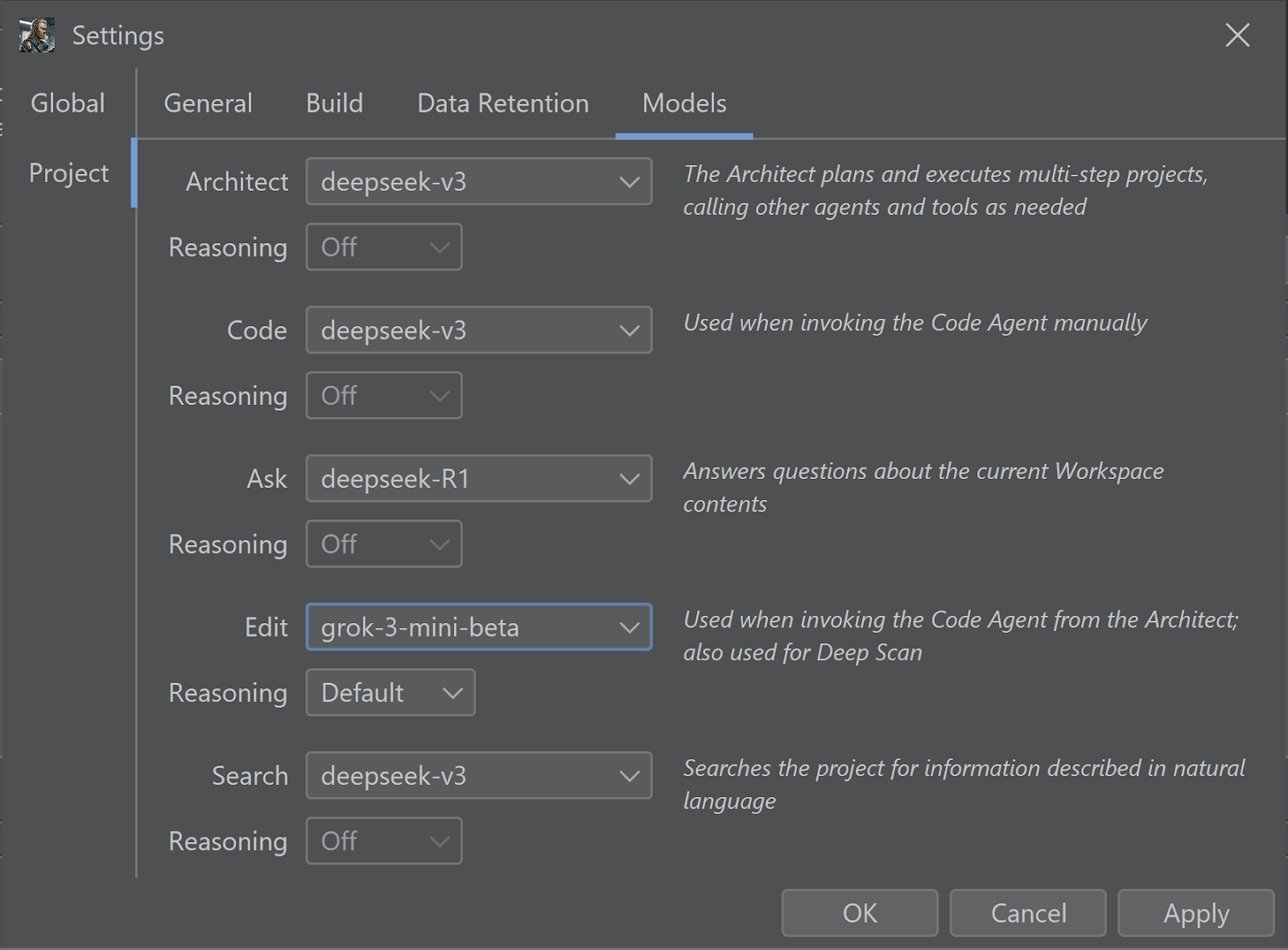
I would prefer to configure Architect and Search to use the reasoning R1 model, but R1 supports neither tool calling nor structured output, so Ask is the place where it most makes sense to use it.
It’s also worth considering Grok 3 Mini in a value-oriented configuration for two reasons.
First, if you don’t want vendors training on your data, then DeepSeek is not an option, and Grok 3 Mini wins automatically. (Grok 3 mini is almost as cheap as DeepSeek v3, and almost as smart.)
Second, Grok 3 Mini supports twice the context length that DeepSeek v3 does, which is very useful for Brokk’s Deep Scan. That’s why I’ve configured it to be used for the Deep Scan-supporting Edit role here.
Brokk offers unlimited free use of both DeepSeek v3 and Grok 3 mini.
Not worth your time: the other OpenAI models
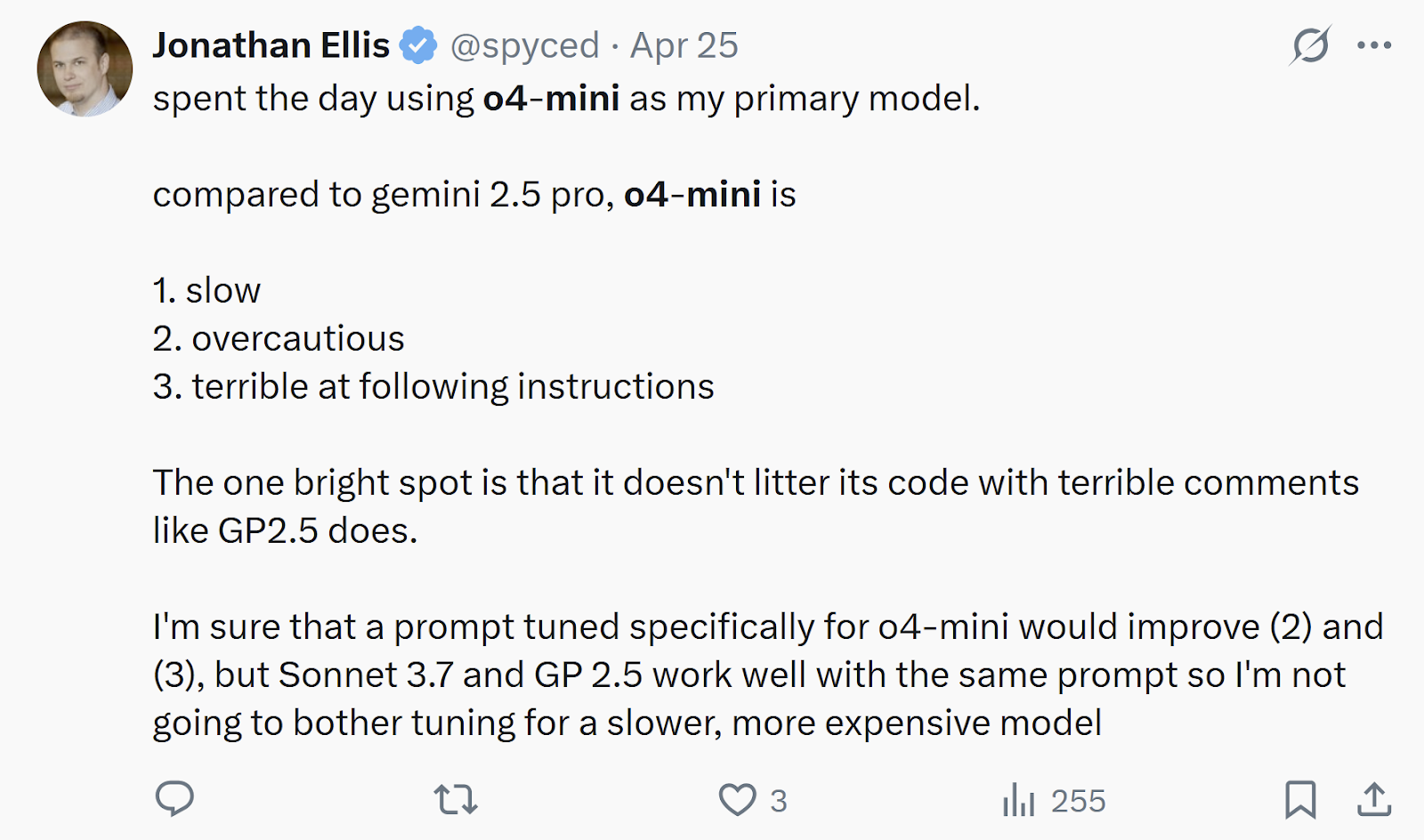
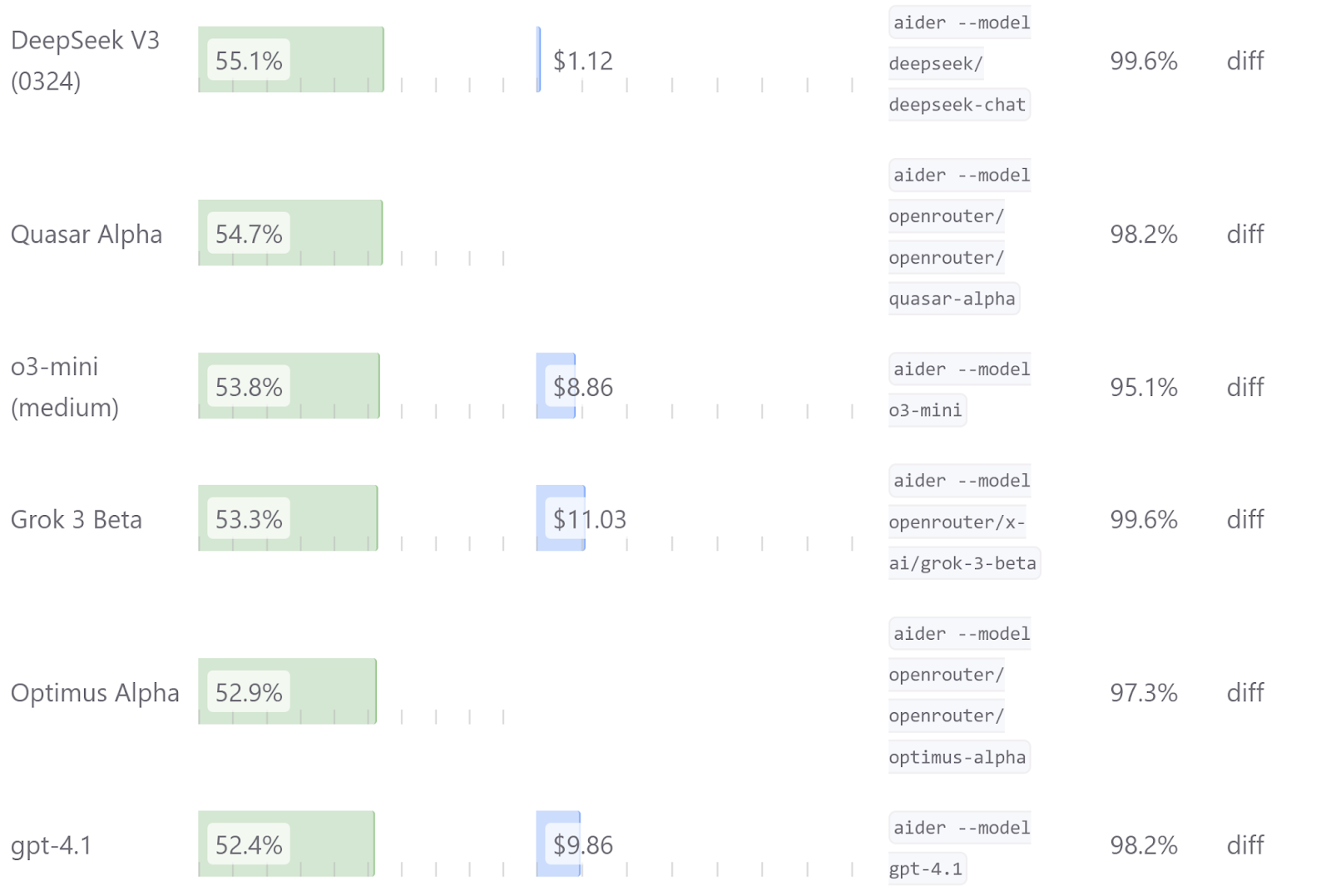
Other than o3, I haven’t been impressed with the current generation of OpenAI models. o4-mini is dumber and slower and more expensive than either Sonnet 3.7 or Gemini 2.5 Pro. GPT 4.1 is faster but even less intelligent, which makes it not quite as smart as DeepSeek v3 but almost 10x more expensive. Here’s Phil Gauthier’s Aider benchmark to quantify that:
Also not worth your time: local models
No LLM that you can run on your own hardware is competitive with any of the frontier models here. Sorry. Not even the latest from Microsoft Research, released last week:
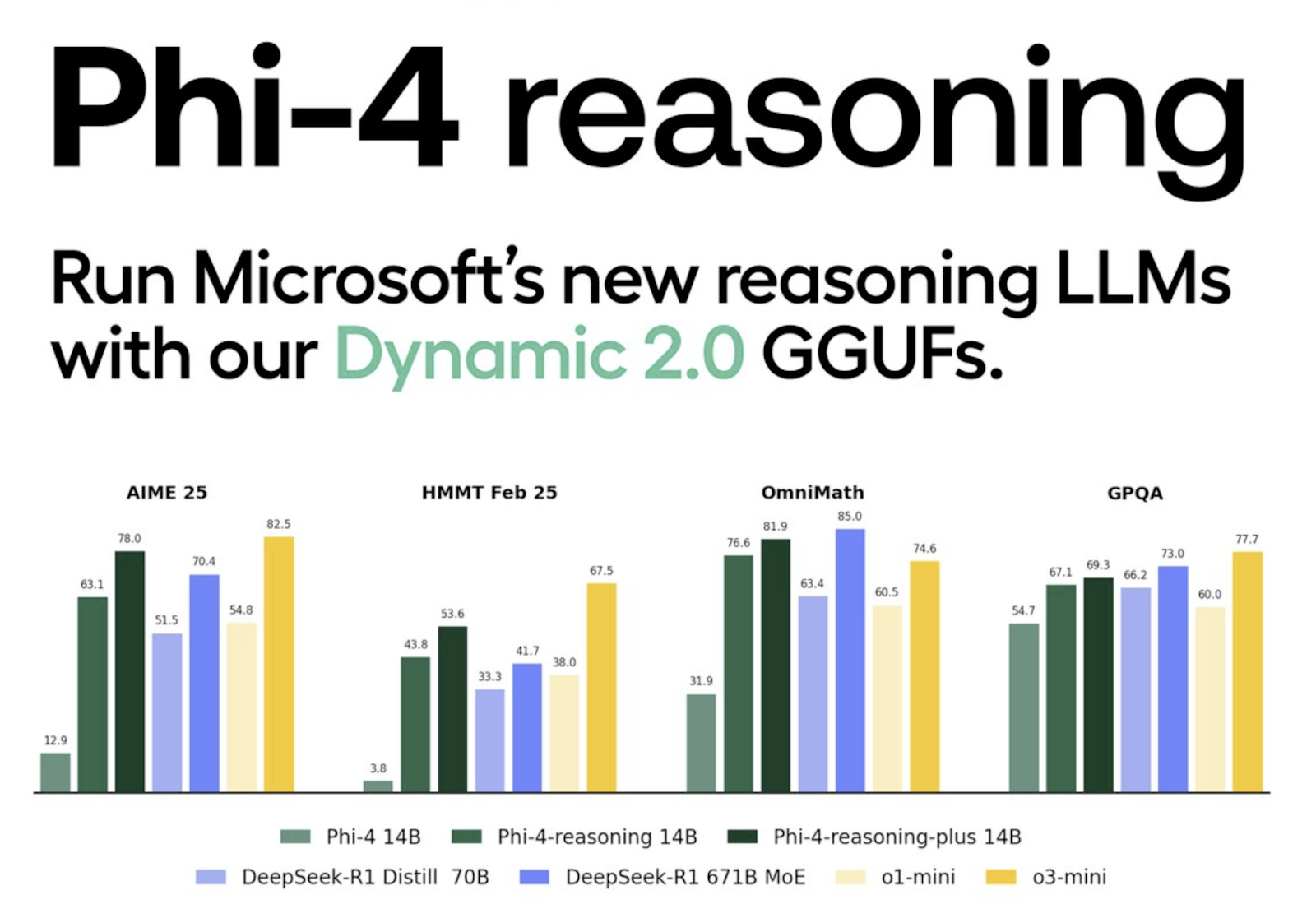
Competitive with o3-mini and R1 seems pretty good! But what all of these benchmarks have in common is that they’re all in math, a domain that has turned out to be much easier for small models to tackle than code. Small coding models that can achieve similar relative performance are not here yet.
Shameless plug
The best way to leverage the intelligence of o3, Gemini 2.5 Pro, and Sonnet 3.7 is Brokk. We’re building Brokk because you can’t take full advantage of AI’s strengths by bolting some plugins onto an IDE following thirty-year-old patterns designed for human-speed reading and writing of code. Brokk rethinks the coding experience from the ground up around supervising AI instead of reading and writing code by hand a line at a time. Try it out!



