
Building a JavaScript Reference Graph With an Agent
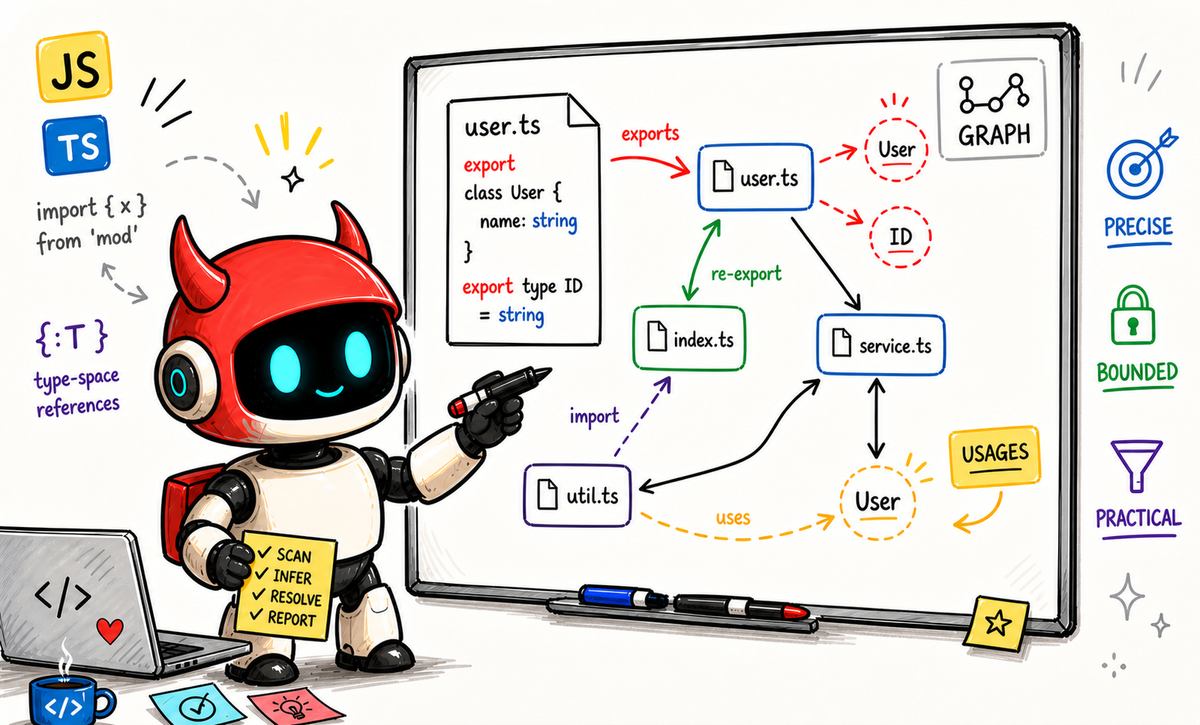
At Brokk we build tools that make LLMs more effective by providing the right context faster than an agent could recover it with grep alone. One such tool is reference analysis: finding where a declaration is actually used in a codebase.
Building production-grade reference analysis by hand is usually a long, careful engineering project. If you want it to be fast, explainable, and resistant to false positives, you are normally looking at weeks or months of design, implementation, and hardening. In this case, we built a substantial JavaScript/TypeScript reference analysis capability with an agent, guided by a human who set the direction and constraints. The value was not just that the agent wrote code quickly. It was the engineering loop around it - domain expertise, targeted tests, review feedback, and repeated refinement - that let us converge much faster than we could have done manually.
This post is about how that worked, what was useful, and where the real leverage came from.
Good direction mattered more than clever prompting
If you think LLMs are "stochastic parrots", this project does not really disprove that. It reinforces that raw model capability is not enough; what mattered was a concrete problem statement, explicit constraints, clear non-goals, and continuous correction.
This did not start from a one-line prompt. I had already spent time working through the shape of the problem, including some back-and-forth with Gemini Pro 3 to get the issue framing into decent shape. That initial issue description was detailed on purpose. Reference analysis is one of those areas where a vague request produces a vague implementation. You need to be clear about the target behaviors, the non-goals, and the constraints:
- Declaration-first rather than speculative search: Queries start at a declaration, never a usage.
- No full TypeScript type checker: Use on-demand, flow insensitive analysis for fast results.
- Bounded, explainable inference for extensibility and easy maintenance.
- Low tolerance to false positives, since we still have the
grepalternative for high recall. - Regression tests for real-world patterns, not only happy paths.
I also came into this as a domain expert. I have built similar systems before, so I had a reasonable mental model of what the architecture should probably look like. That turned out to be the right setup for an agent: I did not need it to invent the whole field from scratch, I needed it to execute quickly, follow feedback, and keep a lot of moving parts coherent.
> uvx brokk install codex-plugin --force
What the agent was good at
Once the overall direction was clear, the agent was very effective at breaking the work into tranches, refining the design as we learned from failures, implementing changes end-to-end, adding targeted tests with each increment, incorporating pull-request review comments, and chasing down platform-specific issues without losing the larger thread.
That matters because reference analysis is never really "one feature". It is a stack of related capabilities that all have to line up: export graph resolution, reverse seeding through barrels, type-space usage tracking, receiver inference, cache invalidation, TSConfig path resolution, cross-platform path normalization, and UI integration with sane fallback behavior.
For me, the slow part is not writing code. It is having to rebuild the whole problem state every time the work shifts from one fix to the next. The agent carried much more of that continuity than I could have done comfortably by hand.
Planning in AGENTS.md was unexpectedly useful
One thing that worked particularly well was capturing and updating the overall design direction in AGENTS.md as the work evolved.
That gave us a durable place to record what the current stage was trying to do, the architecture assumptions, the non-goals, and what kind of tests were now expected after this iteration.
In practice this reduced drift. As the implementation expanded, the agent had a place to anchor on instead of treating every follow-up as a fresh blank slate.
The real quality lift came from negative tests
The happy path was never the main risk. It is easy to build something that works for direct imports, direct exports, and one obvious usage.
The trouble starts when real code gets in the way: barrel re-exports through index.ts, constructor parameter-property type references, and TSConfig alias expansion through inherited config. Those are exactly the kinds of cases that do not show up in a toy example but immediately matter in a real codebase.
Once those cases started surfacing, the testing strategy changed. We stopped treating them as odd edge cases and started pinning them with focused regressions. That included positive cases like barrel re-exports, but also negative cases like destructuring and object property keys, where a broad tree walk can easily mark the wrong names as shadowing.
One concrete example of barrel re-exports is below. Naive usage analysis often follows exports forward, but misses the fact that LayoutService in header.component.ts still refers back to the declaration in layout.service.ts through the local barrel in index.ts.
// layout.service.ts
export class LayoutService {
applyLayout() {
return "grid";
}
}
// index.ts
import { LayoutService } from "./layout.service";
export { LayoutService };
// header.component.ts
import { LayoutService } from "../core/utils";
export class HeaderComponent {
constructor(private layoutService: LayoutService) {}
render() {
return this.layoutService.applyLayout();
}
}Snippet taken from ngx-admin.
That pattern was important: whenever we found a bug, we tried to pin it with a focused regression before or alongside the fix.
A big lesson here is that true negatives and false positives deserve first-class tests. Every time we added one of those tests, it forced the implementation (and our sycophantic agent) to become more honest.
PR review was not just cleanup, it changed the implementation
The back-and-forth with brokk-bot (our code review bot) on the PR was genuinely useful. A good example is that the review was not limited to style or small nits. It surfaced things like:
- self-managed caches that did not fit the analyzer snapshot design model
- potential stale cache behavior across incremental updates
- owner identity problems that could cause false positives across files with similarly named classes
- performance concerns in repeated shadowing scans and repeated project-wide re-computation
That is exactly the kind of review input that helps a system like this mature. It is one thing to get the feature working from the initial working implementation. It is another thing to make the implementation match the lifecycle and performance constraints of the host system.
The useful part was that the agent could absorb those review comments and turn them into concrete follow-up work quickly. That compressed the review-to-fix cycle a lot.
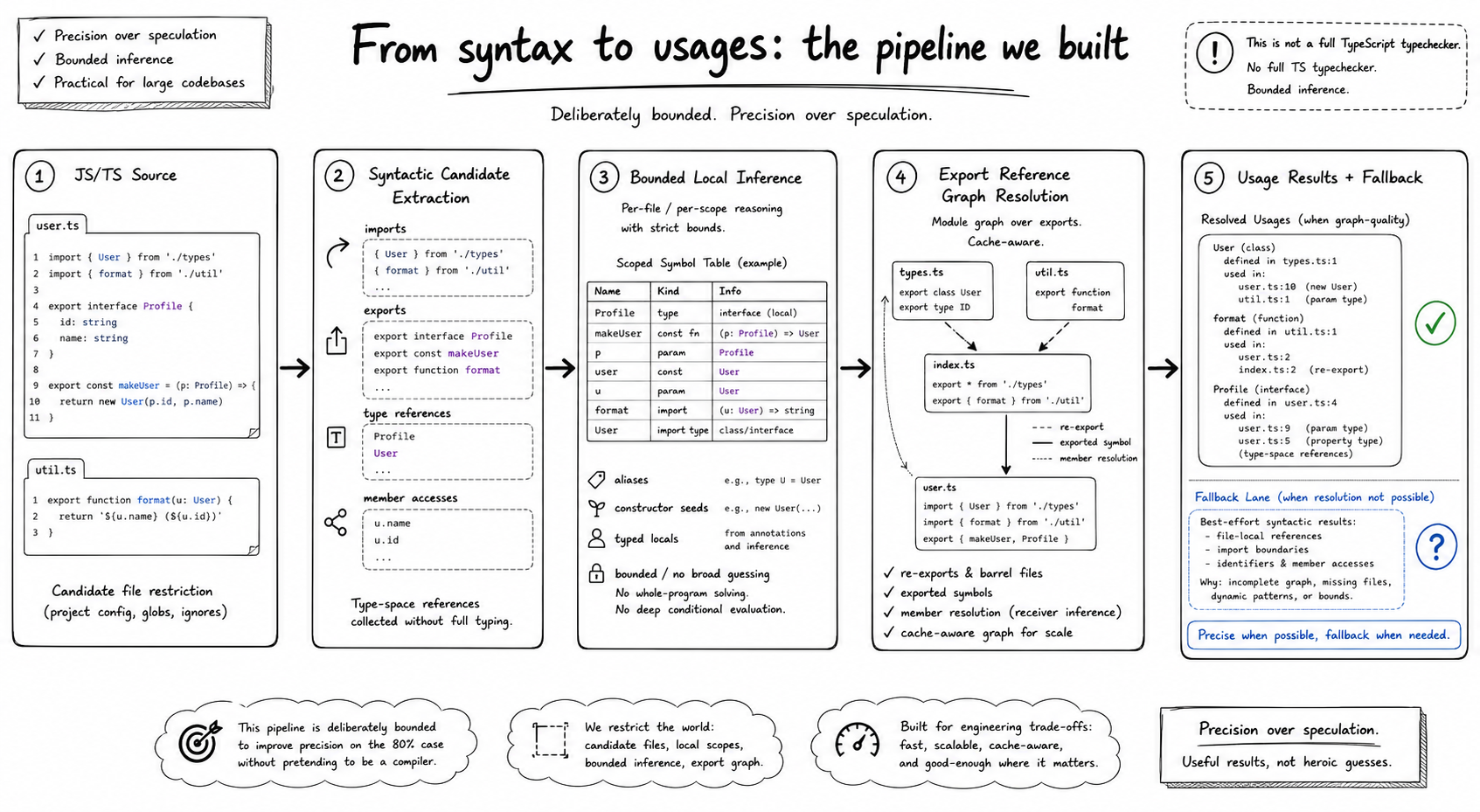
What still needed human judgment
This was not a case of throwing a vague prompt at an agent and getting a production feature back.
The initial issue was detailed, but it was only detailed because I had already spent time iterating on the design with Gemini Pro and because I have built similar systems before. The agent was strong at turning that direction into code, tests, and follow-up fixes. It was not magically inventing the architecture from scratch. It was also not eager to stop and plan first.
Human judgment mattered most in three places.
First, setting the boundaries. We were deliberately not adding a TypeScript type checker, not doing flow-sensitive inference, and not widening unknown receivers from unseen library code into broad speculative matches.
Second, deciding what counted as success. We did not just test happy paths. We added true negatives and false-positive guardrails consistent with our precision boundaries: unknown receivers should not match every member, object literals with the same property name should not count, local shadowing should still block imported bindings, and ambiguous inference should stop rather than guess.
Third, reviewing the shape of the implementation. The most useful review comments were often architectural rather than syntactic: caches that were "self-managed" instead of part of our existing unified AnalyzerCache class, repeated whole-project re-computation at certain points, and path handling that quietly broke on Windows.
What I would do differently next time
I would make the iterative plan a first-class artifact, using PLANS.md or something similarly explicit, because it was an implementation plan and set of constraints, not just coding conventions. In this run, updating AGENTS.md worked, but the broader lesson is that long-running agent work benefits from a living design document that captures both the intended architecture and the known non-goals.
I would also bias even earlier toward adversarial tests. The happy path moved quickly, but the real quality came from asking questions like: what should happen if two files both declare Foo.bar? What if a TSConfig path alias uses wildcard templates on Windows? What if the code is technically resolvable but doing so would explode false positives?
One thing I would have to emphasize is that this would not be possible without real domain expertise and someone who has done something similar before. The person steering the agent needs a decent feel for what a realistic, maintainable scope looks like; it is too easy for the agent to drift toward bad trade-offs or impressive-looking, but impractical results.
For those interesting in diving deep into the Codex session, you can find that below, and check out the branch dave/jsts-export-usages-ir on the Brokk application repository to sync with the session.