
SlopCop: Forensics for your codebase
SlopCop started from a familiar problem: agents can write code quickly, but they do not always write code that belongs in the repo.
They miss local conventions. They recreate helpers that already exist. They add comments nobody asked for. They produce code that works today but is awkward to read, hard to extend, or worse than it needs to be at scale.
That is the “slop” SlopCop looks for: code that adds technical debt; that quietly makes the next change a little bit harder, and the next after that.
SlopCop's goal is to make agents part of the solution that they're causing. It sends specialist agents into the codebase with static analysis tools, then turns the findings into a case file: complexity hotspots, duplicated structures, weak tests, failure handling that hides problems, out of date or unhelpful comments. SlopCop concludes with concrete recommendations for what to fix next.
When to use SlopCop
SlopCop can be fun to run on a repo just to see how far up it lands on the Most Wanted wall. It is good for curiosity, comparisons, and a bit of bragging rights.
But it is also meant to be useful. If you are joining a project, maintaining an older codebase, or reviewing AI-generated changes, SlopCop gives you a structured read on maintainability risk.
Later in this post, we will get into how the findings work, how the recommendations are produced, and what shows up in the case file. The short version is that a good scan should leave you with concrete moves: split this module, delete this unused layer, tighten this test, reuse this helper, stop swallowing this error, add this lint rule, or write this down in AGENTS.md so the next agent does not repeat the same mistake.
You can treat it as a wall of shame, a scorecard, or a serious report. The useful part is that it points you toward the changes most likely to make the codebase easier to live with.
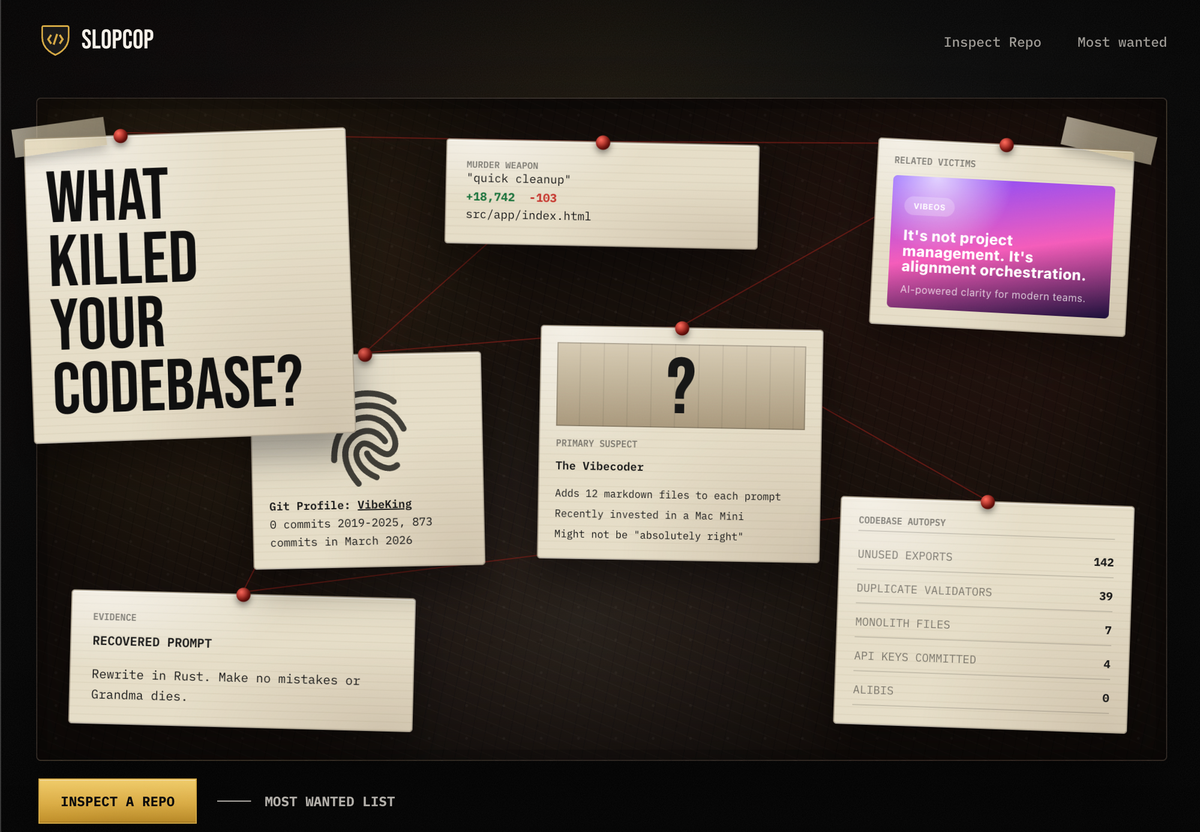
The Most Wanted Wall
The Most Wanted wall is a public slop scoreboard where you can "show off" your slop score:

Public scans can be pinned as case files, ranked by score, and opened as dossiers. Each entry shows the repo, verdict, summary, score, and supporting report.
Yes, it's primarily in fun. Who doesn't love a leaderboard?
How we built it
Linters or static analysis can give false positives or negatives, but they are deterministic and backed by some well-defined policy that matches code evidence. An LLM is intelligent, can present findings in a persuasive paragraph claiming one thing or another, but whether that is true or not is difficult to say without evidence.
SlopCop uses both: static analysis finds leads, agents verify the surrounding code, and the final report gives recommendations a developer or another agent can actually use.
We tuned SlopCop by running it against real repositories, looking at where it failed, and tightening the prompts, routing, and scoring until the results were harder to fool. We benchmarked different step limits, model setups, and report shapes, then checked whether the output actually held up when humans reviewed the evidence.
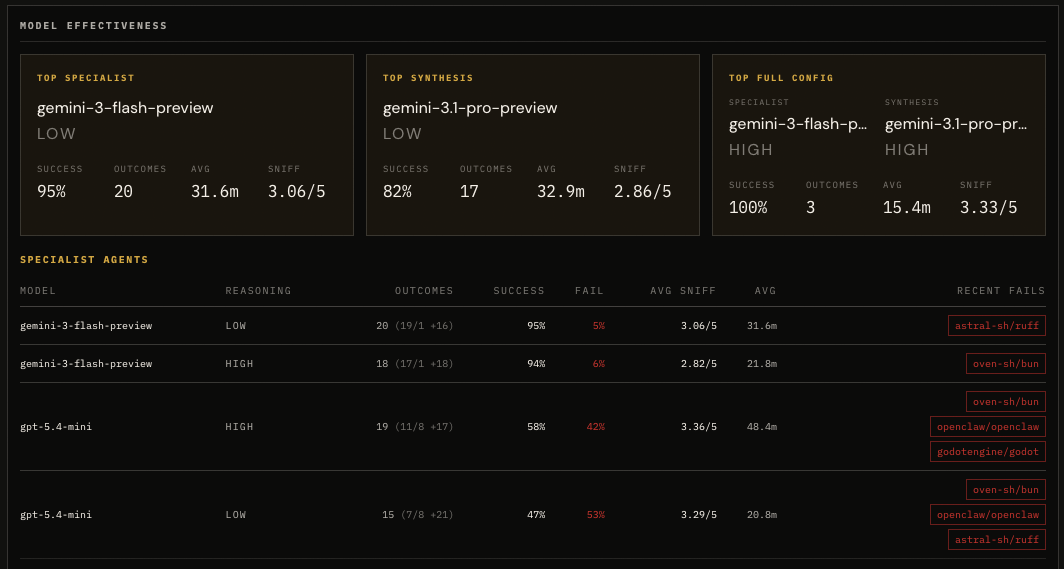
There’s a slightly meta part to this where in some cases the job starts to look like a reverse Turing test: can we tell whether this mess came from a person, a model, or both? We audited the sniff test the same way we audited the rest of the system; if a report sounded confident but wasn’t precise, or if the scoring rewarded the wrong thing, we changed the rubric. The report needs to be useful, and it needs to acknowledge where the evidence is weak.

If the next step is going back to an LLM, the prompt should already know which files matter, which pattern was suspicious, and what kind of fix would help. Acknowledging this led to the creation of the “Copy Recommendation as Prompt” feature. Sometimes that means code changes. Sometimes it means a lint rule, a CI check, or an AGENTS.md entry that tells future agents which utilities and conventions to use.

Why Specialists?
We found that a single reviewing agent, even with a deep bag of tools, tends to smooth every issue into the same advice. SlopCop splits the work across specialists because different kinds of slop need different instincts.
For large repositories, this split also helps us to scale. A single "do everything" agent can be slow, lead to "out of context" errors, and even cause hallucinations. Breaking up work is a way to parallelise bite-sized investigations into multiple lanes. Some of the agents SlopCop uses include:
- The Cognitive Complexity agent looks for code that is hard to hold in your head: nested branches and tangled control flow that make change risky.
- The Size and Sprawl agent looks for long methods, god objects, oversized modules, and workflow files that became dumping grounds with no clear separation of concerns.
- The Structural Duplication agent hunts for repeated shapes: copy-paste variants, parallel helper stacks, and tiny homemade frameworks that scatter future changes across near-copies.
- The Error Handling agent checks for empty catches, broad fallbacks, swallowed failures, and log-and-continue paths that make broken behavior look normal until it blows up at a point far removed from the actual problem.
- The Dead Code and Abstraction agent looks for old weight: unused declarations, generated-code residue, one-call abstractions, and once-clever layers that no longer earn their keep.
- The Test Signal agent asks whether the tests prove anything useful. A green check is only useful if the test would fail for the right reason.
- The Comment Intent agent starts with comment density, then checks whether the comments are useful. “Why this exists” is valuable. “This loop loops over the list” is noise.
Finally, a synthesis pass pulls the notes together, removes duplicates, weighs the evidence, and writes the final report.
The Important Part: Tools
SlopCop gives agents static analysis tools from the same code intelligence stack used by Brokk. Many of those signals are heuristic. They surface leads like complexity hotspots, duplication, dead code, weak tests, or swallowed errors, but they don't decide the verdict on their own.
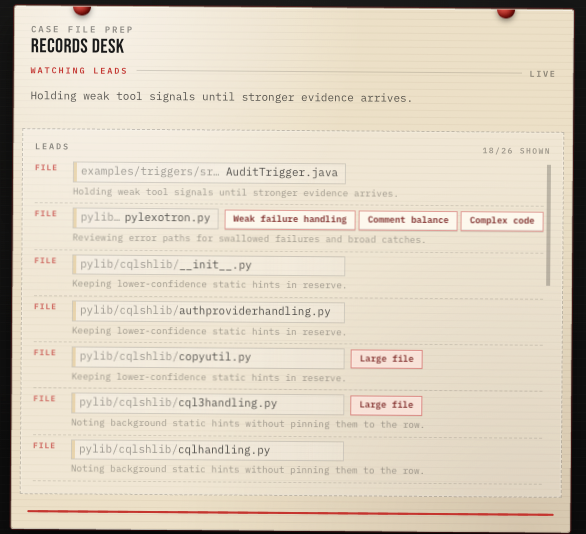
The agent’s job is to read around the signal. Is this real? Is it harmless? Is it worth fixing? If yes, the report should say where the evidence is and what to do about it.
A useful finding has to carry evidence. “This feels messy” is not enough. The report should be able to say: this file is complex, this pattern repeats in these places, this abstraction has one real caller, or this test passes without proving the behavior.
SlopCop is here to help you, not to replace you
At Brokk, humans direct agents to write code, tools find suspicious patterns, agents verify the evidence, and humans decide what is worth fixing. Then the recommendations feed into the next pass, with better context than the first one had.
Our goal with SlopCop is to help tame the slop firehose; if it merely adds another layer to it, we have failed. AI is going to do almost all of the code-tokens authoring in the future, which means we humans need better ways to inspect it, steer it, and clean it up. Preferably with receipts.
File a warrant and see what turns up.